12.3. Bayesian methods to deal with outliers#
Bayesian approaches to erratic data#
We’ll consider four Bayesian approaches to outliers:
A conservative model (treat all data points as equally possible outliers).
Good-and-bad data model.
The Cauchy formulation.
Many nuisance parameters.
First, let’s preview our approaches by considering what is problematic about a Gaussian model for the observation errors when we have outliers.
Why are outliers problematic with a Gaussian model?#
As noted already, with a Gaussian log likelihood,
in units of \(\sigma_0\) it costs a lot to have an outlier \(y_j\) far from \(y_M(x_j;\boldsymbol{\theta})\) (i.e., to have an outlier with respect to the current model). This distorts the fit of the mean value at \(x_j\), namely \(y_M(x_j;\boldsymbol{\theta})\). Let’s see how that distortion works analytically.
Suppose we first calculate the log likelihood with \(N\) points, none of which are outliers. Then the maximum likelihood parameters \(\boldsymbol{\widehat\theta}\) are such that
Now hold \(\boldsymbol{\widehat\theta}\) fixed but add a new outlier point \((x_j,y_j)\). What happens to the maximum likelihood condition? Only the new term in the sum will contribute because the derivatives of the other will sum to zero when \(\boldsymbol{\theta} = \boldsymbol{\widehat\theta}\). So now
where only the first factor depends on \(y_j\). Thus this factor will grow without bound:
and therefore the parameters in \(\boldsymbol{\widehat\theta}\) are pulled more and more by the single outlier point as the magnitude of the outlier grows. This influence will be the case for any theoretical model, but is intrinsic to the normal distribution for the likelihoo. How to avoid it?
One possibility is to switch to a heavier-tailed distribution that doesn’t have this property of unbounded influence. For example, replace the normal distribution by Student’s t-distribution (here this is any \(i\)):
with \(\mu = y_M(x_i;\boldsymbol{\theta})\) and \(\sigma = \sigma_0\) here. Then
and the contribution of \(y_j\) to the minimization of the likelihood is (substituting for \(\mu\) and \(\sigma\))
The t-distribution becomes a Gaussian distribution as \(\nu \rightarrow \infty\), and we see that in that case the derivative will go to infinity like \(y_j - y_M(x_j;\boldsymbol{\widehat\theta})\), as we saw earlier. But for any finite \(\nu\), the \(\bigl(y_j - y_M(x_j;\boldsymbol{\widehat\theta})\bigr)^2\) factor in the denominator with dominate over the \(\nu\sigma_0^2\) factor, and the derivative will vanish as \(y_j \rightarrow \infty\). In other words, the influence on the parameters from the outlier will go away.
In the next section we will see how a heavy-tailed distribution, such as the Student t distribution, can naturally arise in a Bayesian formulation when the uncertainty is itself uncertain.
Approach no. 1: A conservative formulation#
Assuming that the specified error bars, \(\sigma_0\), can be viewed as a recommended lower bound, we can construct a more conservative posterior through a marginal likelihood (that is, we introduce \(\sigma\) as a supplementary parameter for what might be the true error, then integrate over it):
Note that \(\sigma_0\) doesn’t appear in the first pdf in the integrand and \(\boldsymbol{\theta}\) doesn’t appear in the second pdf. The prior is a variation of Jeffrey’s prior for a scale parameter (which would be \(1/\log(\sigma_1/\sigma_0) \times (1/\sigma)\) for \(\sigma_0 \leq \sigma < \sigma_1\) and zero otherwise),
for \(\sigma \geq \sigma_0\) and zero otherwise. (This enables us to do the integral up to infinity.) Conservative here means that we treat all data points with suspicion (i.e., we do not single out any points).
The likelihood for a single data point \(D_i\), given by \((x_i,y_i,\sigma_i=\sigma_0)\), is then
with \(R_i\) the residual as defined above.
Treating the measurement noise as independent, and assigning a uniform prior for the model parameters, we find the log-posterior pdf
We’ll also consider a Cauchy distribution for comparison.
/usr/share/miniconda3/envs/2025-book-env/lib/python3.11/site-packages/arviz/__init__.py:50: FutureWarning:
ArviZ is undergoing a major refactor to improve flexibility and extensibility while maintaining a user-friendly interface.
Some upcoming changes may be backward incompatible.
For details and migration guidance, visit: https://python.arviz.org/en/latest/user_guide/migration_guide.html
warn(
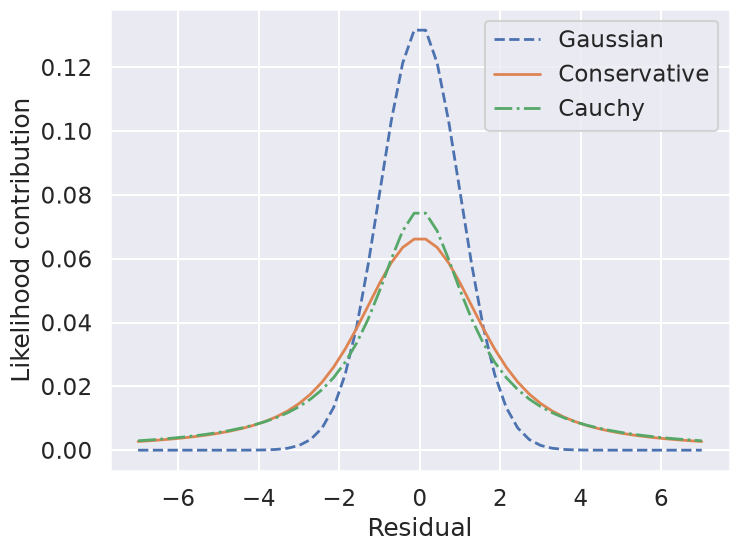
So by marginalizing over the error for each data point, we introduce long tails into the likelihood. The likelihood function is close to a Cauchy distribution in the tails, which is a particular case of a Student \(t\) distribution. (Remember the radioactive lighthouse!)
Now we can sample using this conservative posterior and compare to the others.
If we wanted to get a general Student’s t-distribution, we can do an integration of the variance over an inverse-gamma distribution or, equivalently, integrate over the inverse of the variance with a gamma distribtion. An animation of the integration leading to a t-distribution is created in Student’s t-distribution from Gaussians.
Approach no. 2: Good-and-bad data#
In this approach, we are less pessimistic about the data. In particular, we allow for two possibilities:
a) the datum and its error are reliable;
b) the datum is bad and the error should be larger by a (large) factor \(\gamma\).
We implement this with the pdf for \(\sigma\):
where \(\beta\) and \(\gamma\) represent the frequency of quirky measurements and their severity. If we use Gaussian pdfs for the two cases, then the likelihood for a datum \(D_i\) after integrating over \(\sigma\) is
We won’t provide code for this approach here but leave it to an exercise (see Sivia, Ch. 8.3.2 for more details). However, we will generalize the idea to the extreme in approach #4 below.
Approach no. 3: The Cauchy formulation#
In this approach, we assume \(\sigma \approx \sigma_0\) but allow it to be either narrower or wider:
Marginalizing \(\sigma\) (using \(\sigma = 1/t\)) gives the Cauchy form likelihood (this is a special case of the Student \(t\) distribution):
The log posterior is
Sampling to compare methods#
We’ll use the emcee sampler to generate MCMC samples of our posteriors.
emcee sampling (version: ) 3.1.6
10 walkers:
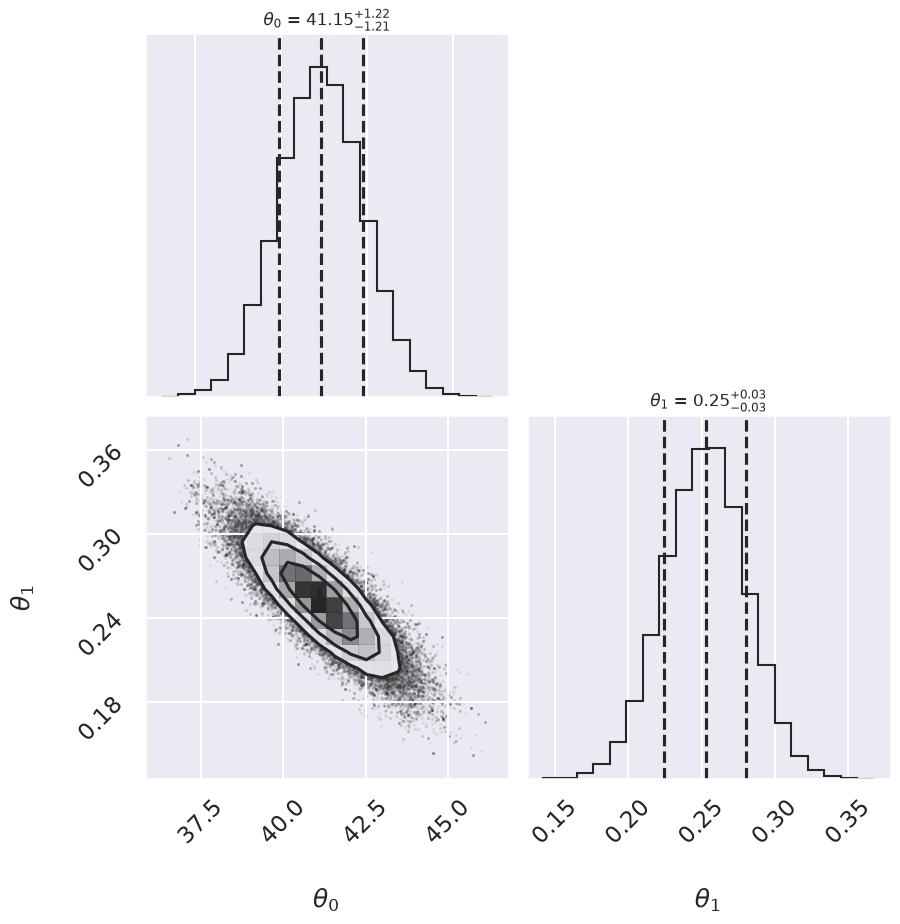
Log posterior: Std Gaussian
... EMCEE sampler performing 1000 warnup iterations.
... EMCEE sampler performing 10000 samples.
CPU times: user 4.14 s, sys: 1.87 ms, total: 4.14 s
Wall time: 4.14 s
done
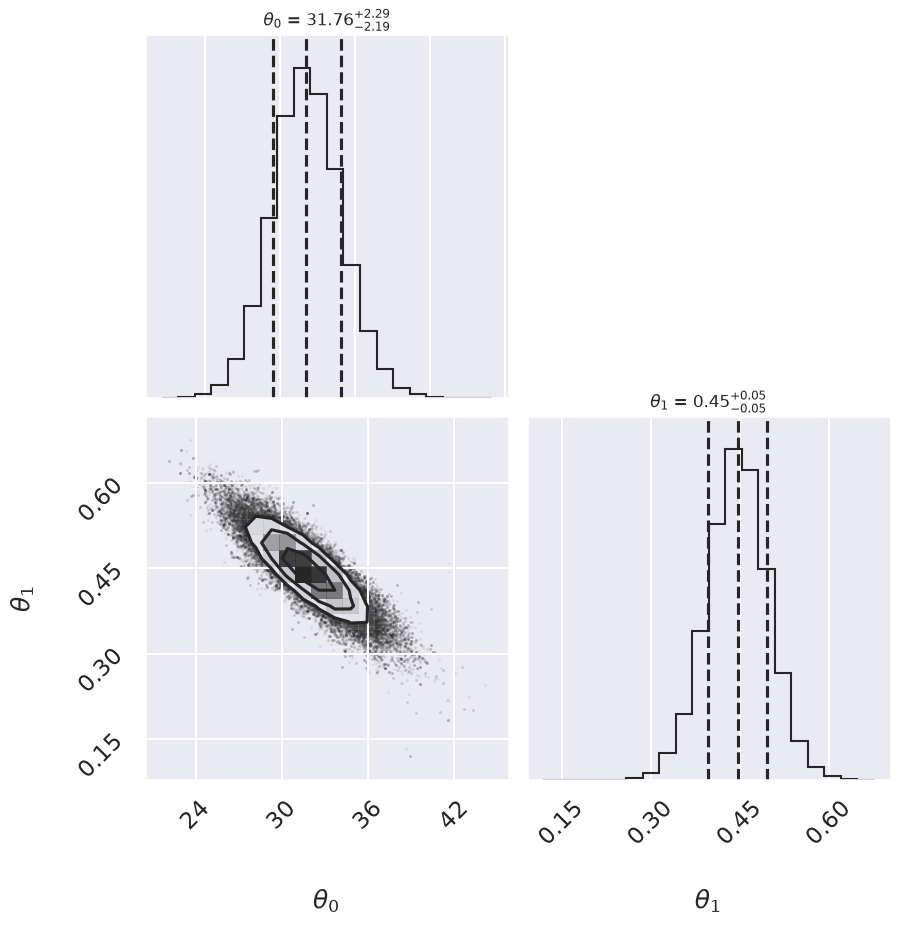
Log posterior: Conservative
... EMCEE sampler performing 1000 warnup iterations.
... EMCEE sampler performing 10000 samples.
CPU times: user 4.68 s, sys: 107 μs, total: 4.68 s
Wall time: 4.68 s
done
Log posterior: Cauchy
... EMCEE sampler performing 1000 warnup iterations.
... EMCEE sampler performing 10000 samples.
CPU times: user 4.52 s, sys: 1.86 ms, total: 4.53 s
Wall time: 4.52 s
done
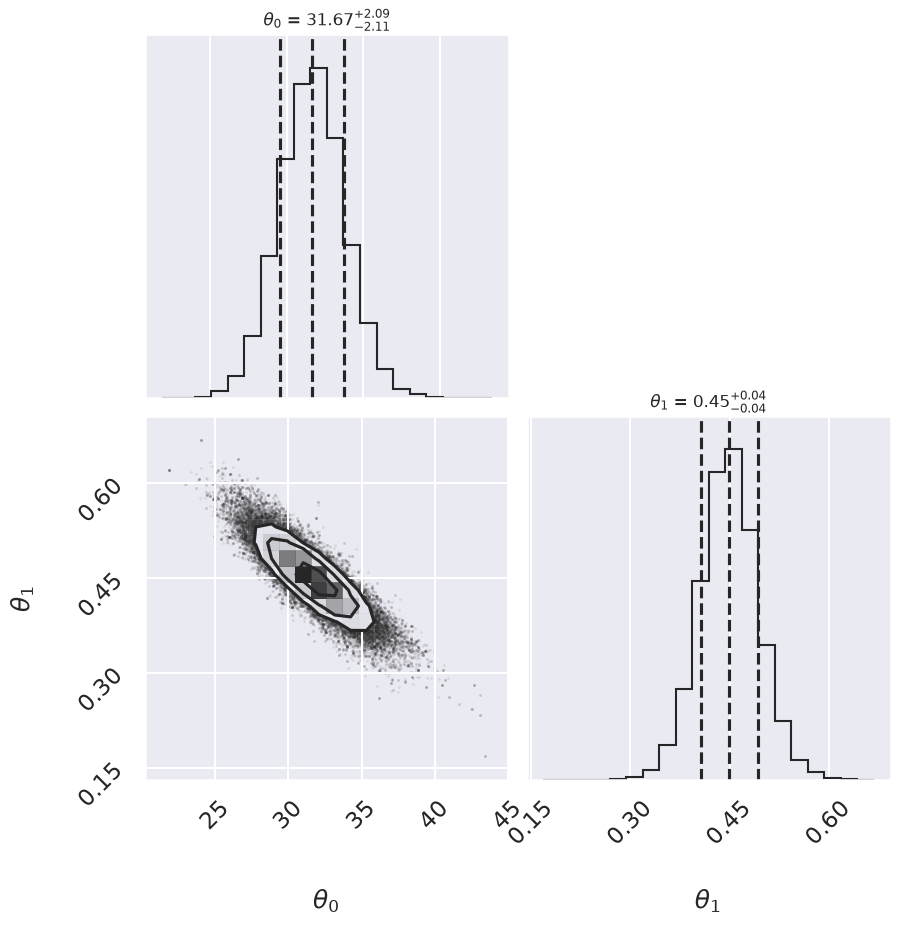
Summary: Mean offset 68% CR Mean slope 68% CR
Std Gaussian 41.15 -1.21,+1.22 0.253 -0.028,+0.028
Conservative 31.76 -2.19,+2.29 0.447 -0.049,+0.050
Cauchy 31.67 -2.11,+2.09 0.449 -0.043,+0.042
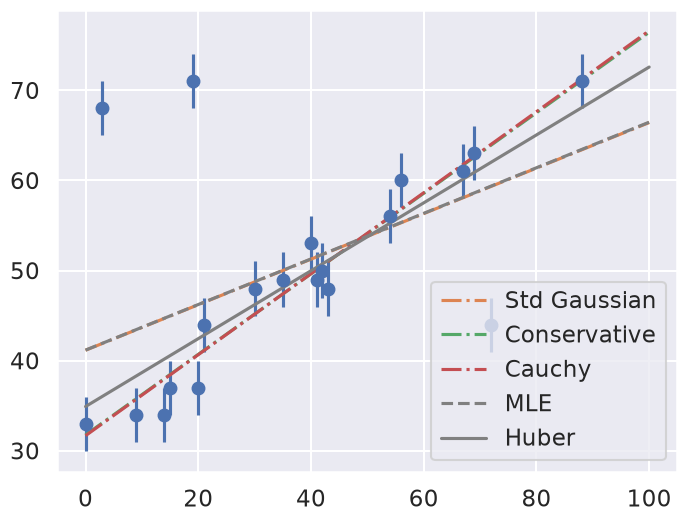
In this plot we see a comparison of five approaches. The standard Gaussian and MLE lines are the same, showing the deleterious effect of the outliers. The Huber loss approach gives a reasonable fit (by eye). The conservative and Cauchy fits are indistinguishable and similar but not identical to the Huber loss fit. Which do you think is better?
Approach no. 4: Many nuisance parameters#
The Bayesian approach to accounting for outliers generally involves modifying the model so that the outliers are accounted for. For this data, it is abundantly clear that a simple straight line is not a good fit to our data. So let’s propose a more complicated model that has the flexibility to account for outliers. One option is to choose a mixture between a signal and a background:
What we’ve done is expanded our model with some nuisance parameters: \(\{g_i\}\) is a series of weights which range from 0 to 1 and encode for each point \(i\) the degree to which it fits the model. \(g_i=0\) indicates an outlier, in which case a Gaussian of width \(\sigma_B\) is used in the computation of the likelihood. This \(\sigma_B\) can also be a nuisance parameter, or its value can be set at a sufficiently high number, say 50.
Our model is much more complicated now: it has 22 free parameters rather than 2, but the majority of these can be considered nuisance parameters, which can be marginalized-out in the end, just as we marginalized (integrated) over \(p\) in the Billiard example. Let’s construct a function which implements this likelihood. We’ll use the emcee package to explore the parameter space.
To actually compute this, we’ll start by defining functions describing our prior, our likelihood function, and our posterior:
Now we’ll run the MCMC sampler to explore the parameter space:
Once we have these samples, we can exploit a very nice property of the Markov chains. Because their distribution models the posterior, we can integrate out (i.e. marginalize) over nuisance parameters simply by ignoring them!
We can look at the (marginalized) distribution of slopes and intercepts by examining the first two columns of the sample:
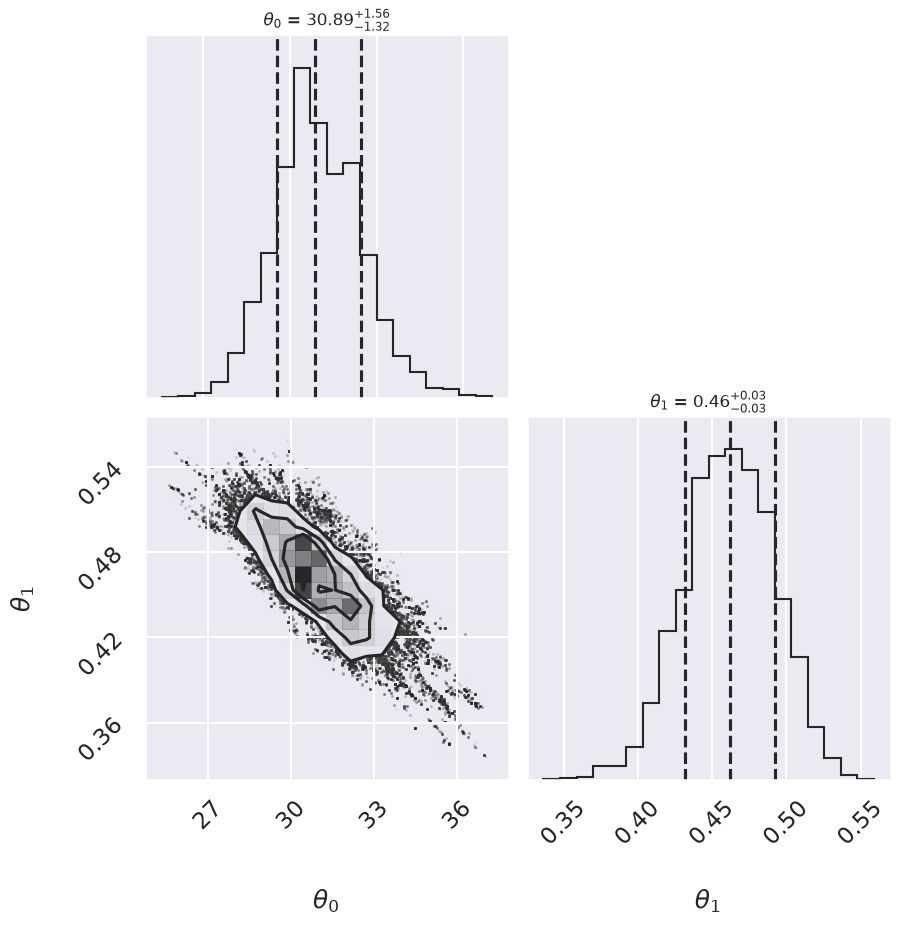
We see a distribution of points near a slope of \(\sim 0.4-0.5\), and an intercept of \(\sim 29-34\). We’ll plot this model over the data below, but first let’s see what other information we can extract from this trace.
One nice feature of analyzing MCMC samples is that the choice of nuisance parameters is completely symmetric: just as we can treat the \(\{g_i\}\) as nuisance parameters, we can also treat the slope and intercept as nuisance parameters! Let’s do this, and check the posterior for \(g_1\) and \(g_2\), the outlier flag for the first two points:
g1 mean: 0.65
g2 mean: 0.39
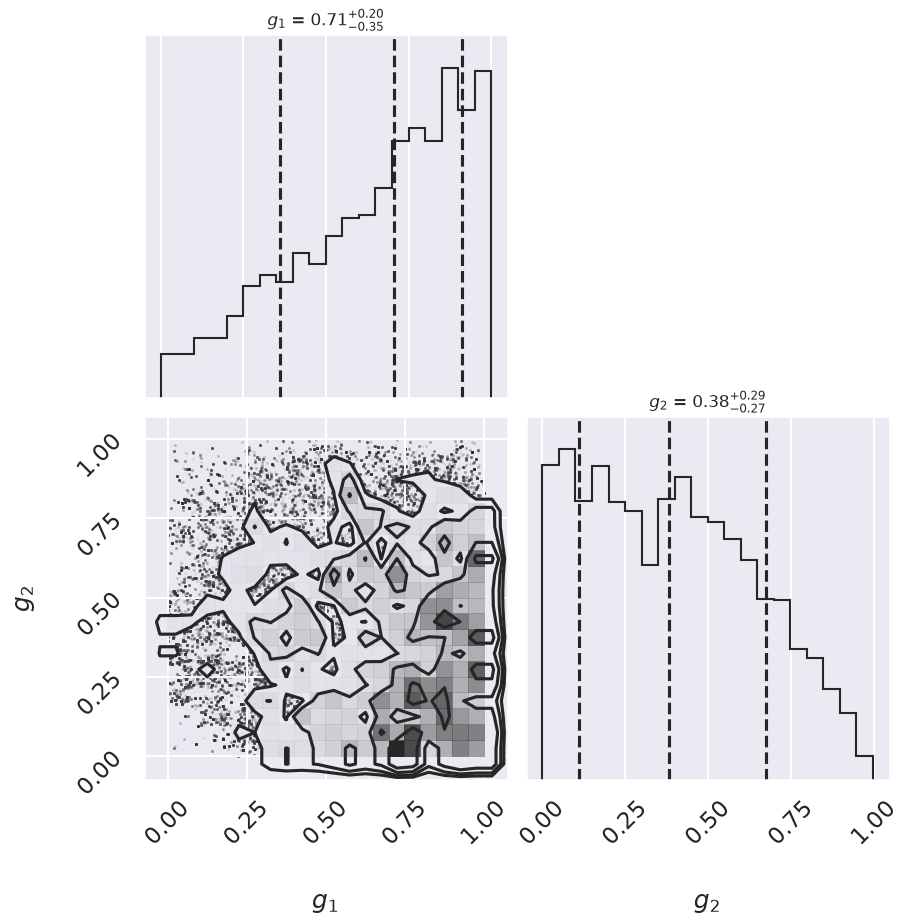
There is not an extremely strong constraint on either of these, but we do see that \((g_1, g_2) = (1, 0)\) is slightly favored: the means of \(g_1\) and \(g_2\) are greater than and less than 0.5, respectively. If we choose a cutoff at \(g=0.5\), our algorithm has identified \(g_2\) as an outlier.
Let’s make use of all this information, and plot the marginalized best model over the original data. As a bonus, we’ll draw red circles to indicate which points the model detects as outliers:
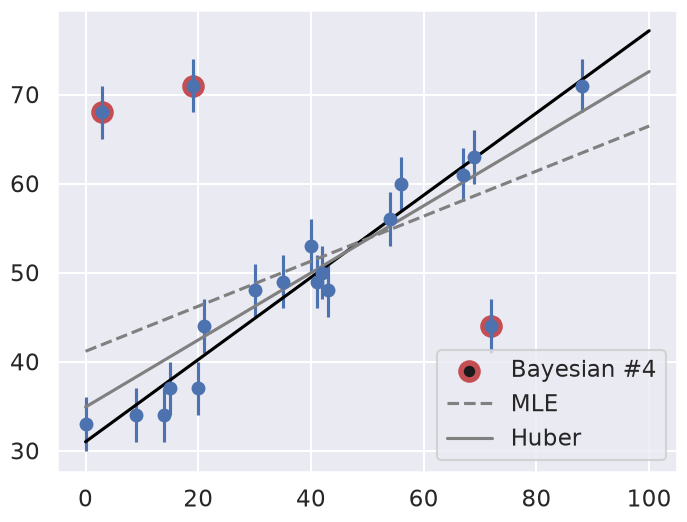
The result, shown by the dark line, matches our intuition! Furthermore, the points automatically identified as outliers are the ones we would identify by hand. For comparison, the gray lines show the two previous approaches: the simple maximum likelihood and the frequentist approach based on Huber loss.
Discussion#
Here we’ve dived into linear regression in the presence of outliers. A typical Gaussian maximum likelihood approach fails to account for the outliers, but we were able to correct this in the frequentist paradigm by modifying the loss function, and in the Bayesian paradigm by adopting a mixture model with a large number of nuisance parameters.
Both approaches have their advantages and disadvantages: the frequentist approach here is relatively straightforward and computationally efficient, but is based on the use of a loss function which is not particularly well-motivated. The Bayesian approach is well-founded and produces very nice results, but it is much more intensive in both coding time and computational time. It also requires a specification of a prior that must be motivated. The advantage is that this prior choice can be tested and compared to alternatives. While you will often see this choice described in the literature (mostly older literature now) as “subjective”, in fact it is a more objective approach because of the ability to evaluate it!