12.1. Setup: linear regression with data outliers#
We will use as our canonical example a set of data that mostly lies close to a straight line, and is expected to lie on a straight line, but has several points that are far away. (This example and subsequent discussion was adapted from the blog post Frequentism and Bayesianism II: When Results Differ.)
Sample dataset#
Consider the following plotted dataset, relating the observed variables \(x\) and \(y\), with errors on \(y\). (You will have the opportunity to explore different datasets and errors in 📥 Demo: Illustrating approaches to outliers.)
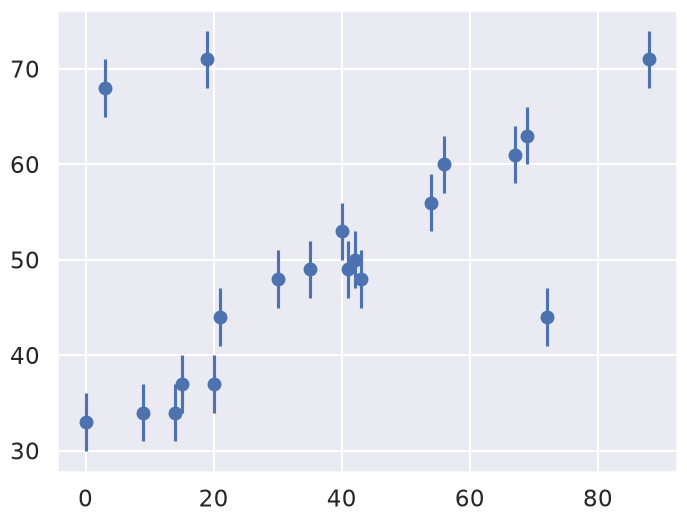
Our task is to find a line of best-fit to the data. It’s clear upon visual inspection that there are some outliers among these points, but how do we deal with them. In the subsequent sections we will consider both frequentist and Bayesian approaches. But first we need to set up our model.
The Model#
Here we review the procedure for fitting a straight line to data, emphasizing the role of the statistical model. We take as our model (“\(M\)” here stands for “Model”; elsewhere we use “th” for theory),
where our parameter vector will be
But this is only half the picture: what we mean by a “model” in a Bayesian sense is not only this expected value \(y_M(x;\boldsymbol{\theta})\), but a probability distribution for our data. That is, we need an expression to compute the likelihood \(p(D\mid\boldsymbol{\theta},I)\) for our data as a function of the parameters \(\boldsymbol{\theta}\).
The Bayesian statistical model we employ is that the distribution of data \(D\) is the sum of the distributions for the model, the model discrepancy, and the observation error:
The model discrepancy term \(\delta M\) is in general important to consider, but we will neglect it here (e.g., assuming it is much smaller than \(\delta D\)).
To establish \(\delta D\), we note that here we are given data with simple error bars, which imply that the probability for any single data point is a normal distribution about the true value. In this example, the errors are specified by a single parameter \(\sigma_0\) (again, we neglect \(\delta M\)). That is, \(y_i = D_i\) is given by
or, in functional form,
The (known) variance of the measurement errors, \(\sigma_0\), is indicated in the figure below by the error bars.
Assuming all the points are independent, we can find the full likelihood by multiplying the individual likelihoods together:
For convenience (and also for numerical accuracy) this is often expressed in terms of the log-likelihood:
We often define the residuals (the notation \(z_i\) is also common)
so that the relevant chi-square sum is \(\chi^2 = \sum_{i=1}^N R_i^2\).
The summation term that appears in this log-likelihood is often known as the loss function. This particular loss function is known as a squared loss or chi-squared; but as you can see it can be derived from the Gaussian log likelihood.