12.2. Frequentist methods to deal with outliers#
In this section and the next we will use the data from Setup: linear regression with data outliers. The theoretical model is
where our parameter vector to be determined is
Standard Likelihood Approach#
We can maximize the likelihood (or, equivalently, minimize the loss) to find \(\boldsymbol{\theta}\) within a frequentist paradigm. For a flat prior in \(\boldsymbol{\theta}\), the maximum of the Bayesian posterior will yield the same result. (Note that there are good arguments based on the principle of maximum entropy that a flat prior is not the best choice here; we’ll ignore that detail for now, as it’s a small effect for this problem.)
For simplicity, we’ll use scipy’s optimize package to minimize the loss (in the case of squared loss, this computation can be done more efficiently using matrix methods, but we’ll use numerical minimization for simplicity here).
Maximum likelihood estimate (MLE): theta0 = 41.2, theta1 = 0.25
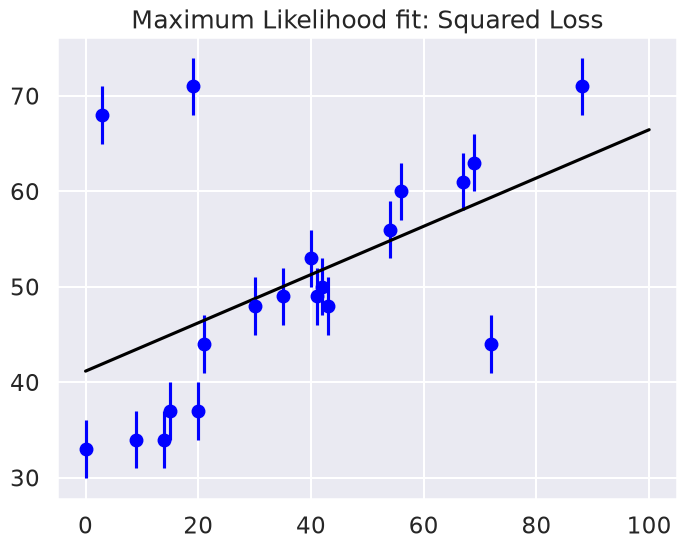
It’s clear on examination that the outliers are exerting a disproportionate influence on the fit. This is due to the nature of the squared loss function. If you have a single outlier that is, say 10 standard deviations away from the fit, its contribution to the loss will out-weigh that of 25 points which are 2 standard deviations away!
Clearly the squared loss is overly sensitive to outliers, and this is causing issues with our fit. One way to address this within the frequentist paradigm is to simply adjust the loss function to be more robust.
Frequentist Correction for Outliers: Huber Loss#
The variety of possible loss functions is quite literally infinite, but one relatively well-motivated option is the Huber loss. The Huber loss defines a critical value at which the loss curve transitions from quadratic to linear. Here is a plot that compares the Huber loss to the standard squared loss for several critical values \(c\):
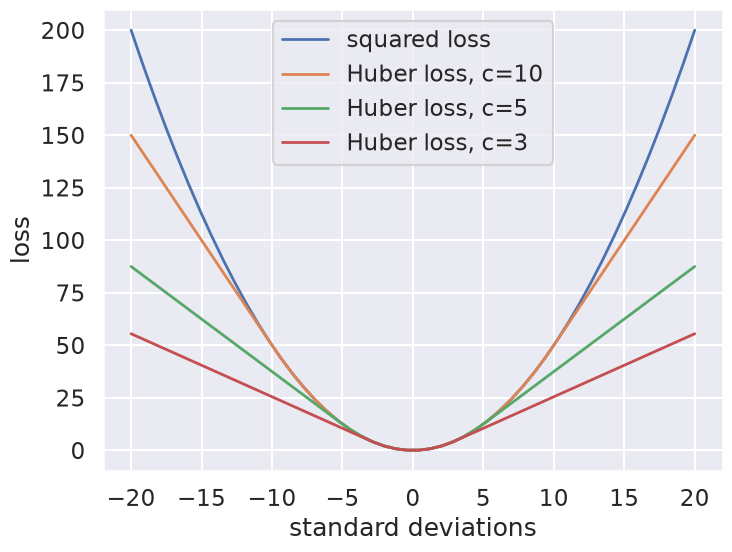
The Huber loss is equivalent to the squared loss for points that are well-fit by the model, but reduces the loss contribution of outliers. For example, a point 20 standard deviations from the fit has a squared loss of 200, but a c=3 Huber loss of just over 55. Let’s see the result of the best-fit line using the Huber loss rather than the squared loss. We’ll plot the squared loss result as a dashed gray line for comparison:
Huber: theta0 = 34.9, theta1 = 0.38
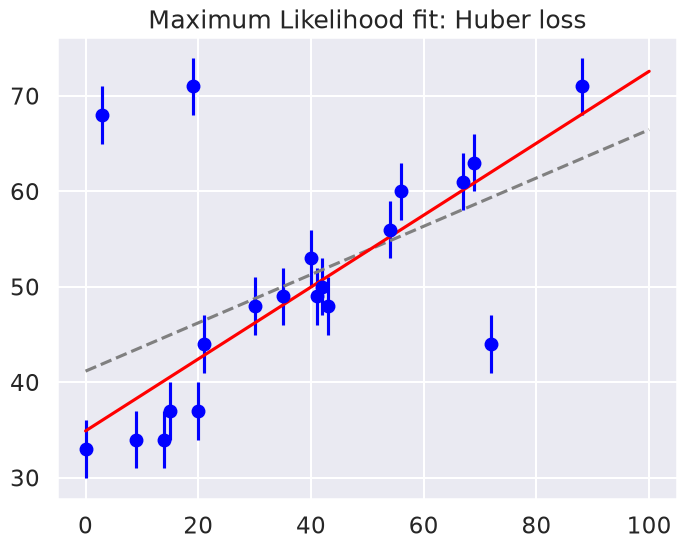
By eye, this seems to have worked as desired: the fit is much closer to our intuition! However, a Bayesian might point out that the motivation for this new loss function is a bit suspect: as we showed, the squared-loss can be straightforwardly derived from a Gaussian likelihood.
The Huber loss seems a bit ad hoc: where does it come from?
How should we decide what value of \(c\) to use?
Is there any good motivation for using a linear loss on outliers, or should we simply remove them instead?
How might this choice affect our resulting model?