Visualizing correlated Gaussian distributions
A multivariate Gaussian distribution for \(N\) dimensional \(\boldsymbol{x} = \{x_1, \ldots, x_N\}\) with \(\boldsymbol{\mu} = \{\mu_1, \ldots, \mu_N\}\), with positive-definite covariance matrix \(\Sigma\) is
\[
p(\boldsymbol{x}|\boldsymbol{\mu},\Sigma) = \frac{1}{\sqrt{\det(2\pi\Sigma)}}
e^{-\frac{1}{2}(\boldsymbol{x}-\boldsymbol{\mu})^\intercal\Sigma^{-1}(\boldsymbol{x}-\boldsymbol{\mu})}
\]
For the one-dimensional case, it reduces to the familiar
\[
p(x_1|\mu_1,\sigma_1) = \frac{1}{\sqrt{2\pi\sigma_1^2}}
e^{-\frac{(x_1-\mu_1)^2}{2\sigma_1^2}}
\]
with \(\Sigma = \sigma_1^2\).
For the bivariate case (two dimensional),
(5.2)\[\begin{split}
\boldsymbol{x} = \begin{pmatrix} x_1\\ x_2 \end{pmatrix} \quad\mbox{and}\quad
\boldsymbol{\mu} = \begin{pmatrix} \mu_1\\ \mu_2 \end{pmatrix} \quad\mbox{and}\quad
\Sigma = \begin{pmatrix}
\sigma_1^2 & \rho_{12} \sigma_1\sigma_2 \\
\rho_{12}\sigma_1\sigma_2 & \sigma_2^2
\end{pmatrix}
\quad\mbox{with }\ 0 < \rho_{12}^2 < 1
\end{split}\]
and \(\Sigma\) is positive definite.
Widget user interface features:
Set the mean position \((\mu_1, \mu_2)\) and variances \((\Sigma_{11}, \Sigma_{22})\) with the sliders
Set the correlation \(\rho_{12}\) with the slider. This controls the covariance \(\Sigma_{12} = \rho_{12} \sqrt{ \Sigma_{11} \Sigma_{22}}\).
Four presets are available.
The corner plot shows samples from the bivariate PDF and histograms for the two marginal distributions. Control the number of samples with the slider.
Dashed lines on the marginals mark the 16th, 50th, and 84th percentiles. This is equivalent to \(\pm 1\sigma\) for a one-dimensional Gaussian.
The solid and dashed ellipses in the joint panel are iso-probability levels. These correspond to fixed values of the squared Mahalanobis distance
\[
\Delta^2 = (\mathbf{x} - \boldsymbol{\mu})^\top \Sigma^{-1} (\mathbf{x} - \boldsymbol{\mu}).
\]
In the widget they are drawn at \(\Delta = 1\) and \(\Delta = 2\). Their semi-axes are aligned with the eigenvectors of \(\Sigma\) and have lengths \(\sqrt{\lambda_i}\) (the “\(1\sigma\)” ellipse) and \(2\sqrt{\lambda_i}\) (the “\(2\sigma\)” ellipse), where \(\lambda_i\) are the eigenvalues of \(\Sigma\).
A subtlety worth highlighting
In one dimension the \(\pm 1\sigma\) and \(\pm 2\sigma\) intervals contain 68.3% and 95.4% of the probability mass. In two dimensions, the corresponding ellipses contain considerably less, because \(\Delta^2 \sim \chi^2_2\) and
\[
\prob(\Delta^2 \le k^2) = 1 - e^{-k^2/2}.
\]
Questions to consider:
What does “positive definite” mean and why is this a requirement for the covariance matrix \(\Sigma\)?
Answer
A symmetric matrix (such as a covariance matrix) is positive definite if all of its eigenvalues are greater than zero. This ensures that
the variance of any linear combination of random variables is non-negative;
that no variable is a linear combination of others (no collinear variables);
the covariance matrix is invertible.
What is plotted in each part of the graph (called a “corner plot”)?
What effect does changing \(\mu_1\) or \(\mu_2\) have?
What effect does changing \(\Sigma_{11}\) or \(\Sigma_{22}\) have? What if the scales for \(x_1\) and \(x_2\) were the same?
What happens if \(\rho_{12}\) is equal to \(0\) then \(+0.7\) then \(-0.7\).
What would happen if you were allowed to set \(|\rho_{12}| \leq 1\)? Explain what goes wrong.
So what characterizes independent (uncorrelated) variables versus positively correlated versus negatively correlated?
2D PDF with a quadratic approximation
Consider a general two-dimensional log likelihood \(L(X,Y)\). We’ll analyze it in a quadratic approximation.
We base our discussion on Sivia section 3.3 [SS06].
First, find the mode \(X_0\), \(Y_0\) (which is the best estimate) by differentiating
\[\begin{split}\begin{align}
L(X,Y) &= \log p(X,Y|\{\text{data}\}, I) \\
\quad&\Longrightarrow\quad
\left.\frac{dL}{dX}\right|_{X_0,Y_0} = 0, \
\left.\frac{dL}{dY}\right|_{X_0,Y_0} = 0
\end{align}\end{split}\]
To check reliability, Taylor expand around \(L(X_0,Y_0)\):
\[\begin{split}\begin{align}
L &= L(X_0,Y_0) + \frac{1}{2}\biggl[
\left.\frac{\partial^2L}{\partial X^2}\right|_{X_0,Y_0}(X-X_0)^2
+ \left.\frac{\partial^2L}{\partial Y^2}\right|_{X_0,Y_0}(Y-Y_0)^2 \\
& \qquad\qquad\qquad + 2 \left.\frac{\partial^2L}{\partial X\partial Y}\right|_{X_0,Y_0}(X-X_0)(Y-Y_0)
\biggr] + \ldots \\
&\equiv L(X_0, Y_0) + \frac{1}{2}Q + \ldots
\end{align}\end{split}\]
It makes sense to do this in (symmetric) matrix notation:
(5.3)\[\begin{split}
Q =
\begin{pmatrix} X-X_0 & Y-Y_0
\end{pmatrix}
\begin{pmatrix} A & C \\
C & B
\end{pmatrix}
\begin{pmatrix} X-X_0 \\
Y-Y_0
\end{pmatrix}
\end{split}\]
\[
\Longrightarrow
A = \left.\frac{\partial^2L}{\partial X^2}\right|_{X_0,Y_0},
\quad
B = \left.\frac{\partial^2L}{\partial Y^2}\right|_{X_0,Y_0},
\quad
C = \left.\frac{\partial^2L}{\partial X\partial Y}\right|_{X_0,Y_0}
\]
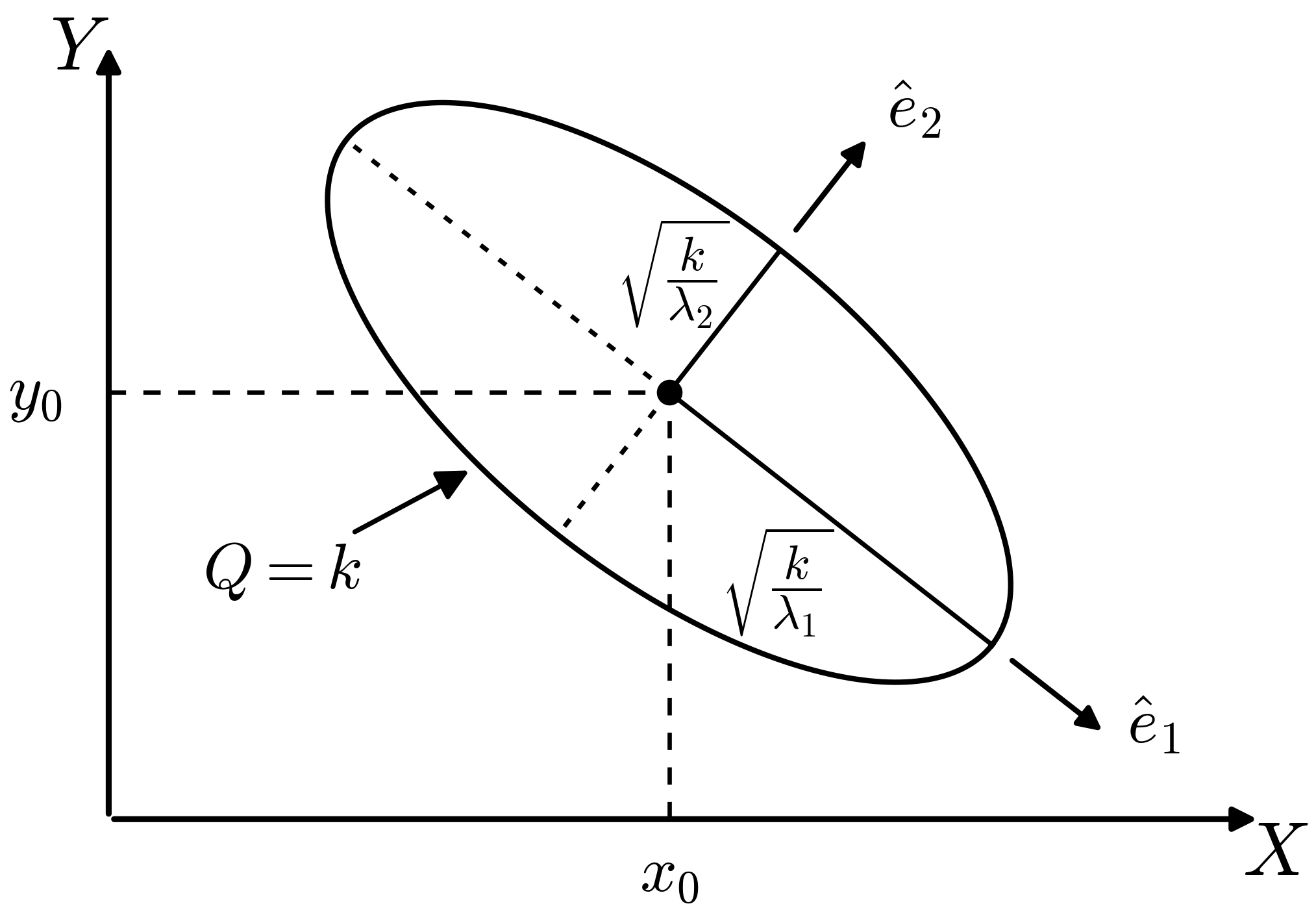
So in a quadratic approximation, the contour \(Q=k\) for some \(k\) is an ellipse centered at \(X_0, Y_0\) (as in the figure). The orientation and eccentricity of the ellipse are determined by \(A\), \(B\), and \(C\).
The principal axes are found from the eigenvectors of the Hessian matrix \(\begin{pmatrix} A & C \\ C & B \end{pmatrix}\):
\[\begin{split}
\begin{pmatrix}
A & C \\
C & B
\end{pmatrix}
\begin{pmatrix}
x \\ y
\end{pmatrix}
=
\lambda
\begin{pmatrix}
x \\ y
\end{pmatrix}
\quad\Longrightarrow\quad
\lambda_1,\lambda_2 < 0 \ \ \mbox{so $(X_0,Y_0)$ is a maximum}
\end{split}\]
Conditions on \(A\), \(B\), \(C\)
The condition \(\lambda_1,\lambda_2 < 0\) for the point \((X_0,Y_0)\) to be a maximum implies that we must have
\[
A < 0, \qquad B < 0, \qquad AB > C^2 .
\]
If the major and minor axes of the ellipse are aligned with the \(x\)-axis and \(y\)-axis (so \(C=0\)), the analysis is simple: the eigenvalues are \(A\) and \(B\) and the error-bars (standard deviations) for \(X\) and \(Y\) will be inversely proportional to the modulus of their square roots.
What if the ellipse is skewed?
If we compare \(Q\) in (5.3) to the bivariate Gaussian exponent (5.2), we can identify the covariance matrix (4.8) in terms of the inverse of \(Q\):
\[\begin{split}
\Sigma_{XY}
=
\begin{pmatrix}
\sigma_X^2 & \sigma_{XY}^2 \\
\sigma_{XY}^2 & \sigma_Y^2
\end{pmatrix}
= - \begin{pmatrix}
A & C \\
C & B
\end{pmatrix}^{-1}
= \frac{1}{AB - C^2}
\begin{pmatrix}
-B & C \\
C & -A
\end{pmatrix}
,
\end{split}\]
from which we can read off the variances and covariance in terms of \(A\), \(B\), \(C\).
When \(C=0\), the covariance \(\sigma_{XY} = 0\) and the values of \(X\) and \(Y\) are uncorrelated.
As \(|C|\) increases from zero, the ellipse becomes increasingly skewed and elongated; this corresponds to greater correlation (with \(C>0\) correlated and \(C<0\) anti-correlated).