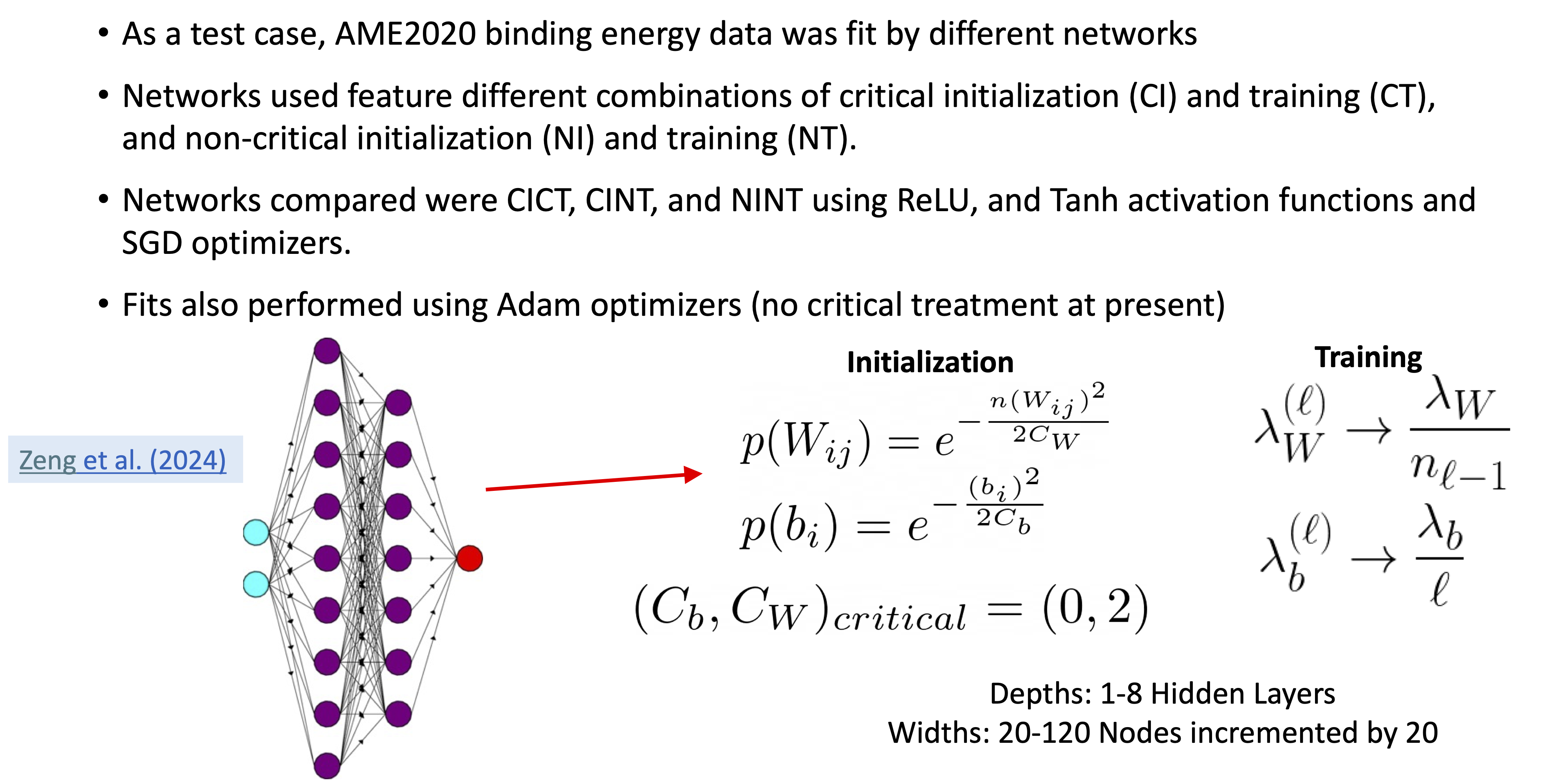
32.7. Critical tuning of hyperparameters#

Mean absolute error loss vs. epochs#
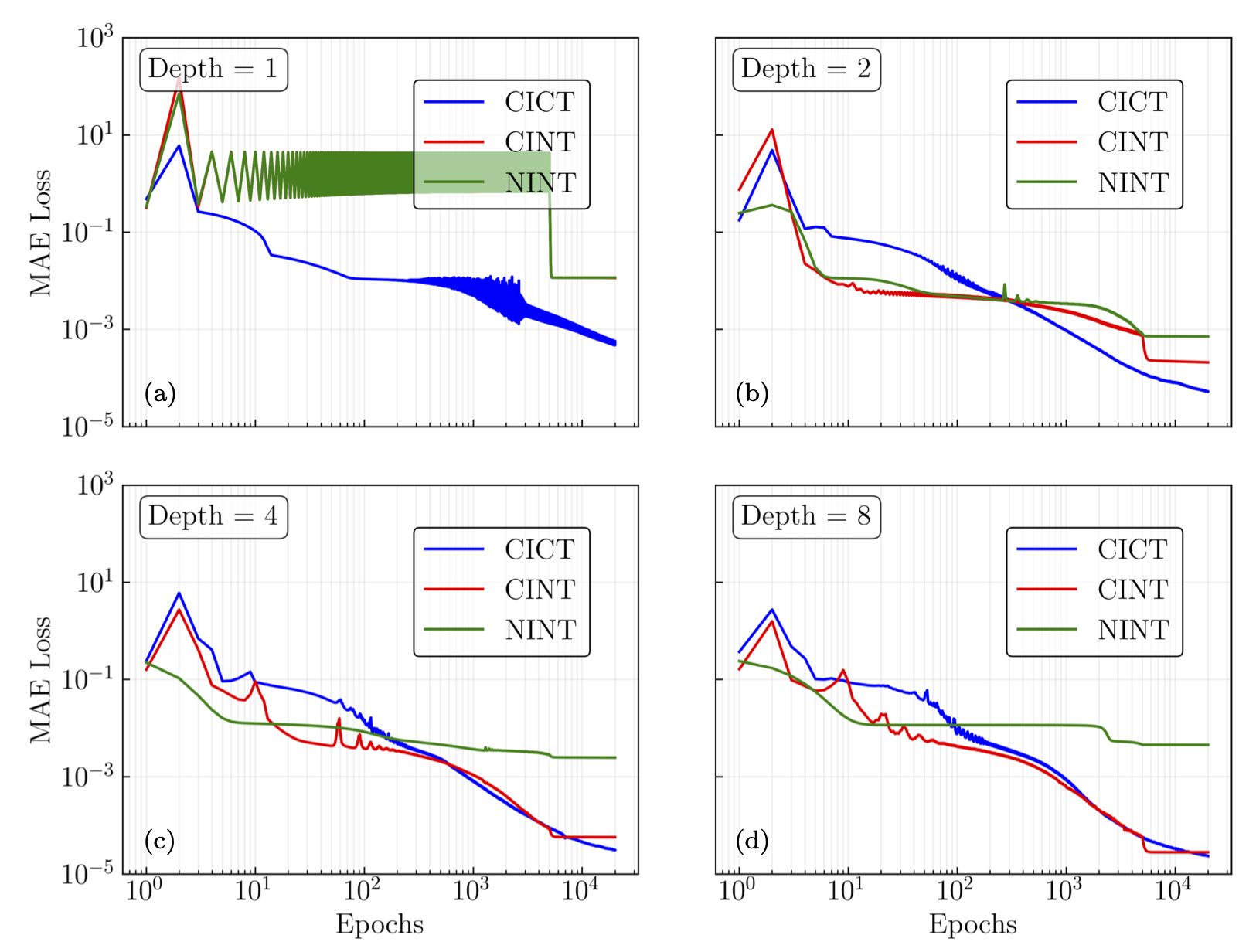
Fig. 32.15 The mean absolute error loss vs. epochs for ReLU activation functions. Hidden layer widths are at 100 neurons, and depths are 1,2,4, and 8 hidden layers. The CICT and CINT architectures outperform the NINT, and their performance improves with depth, whereas the NINT networks stagnate in performance after 2 hidden layers.#
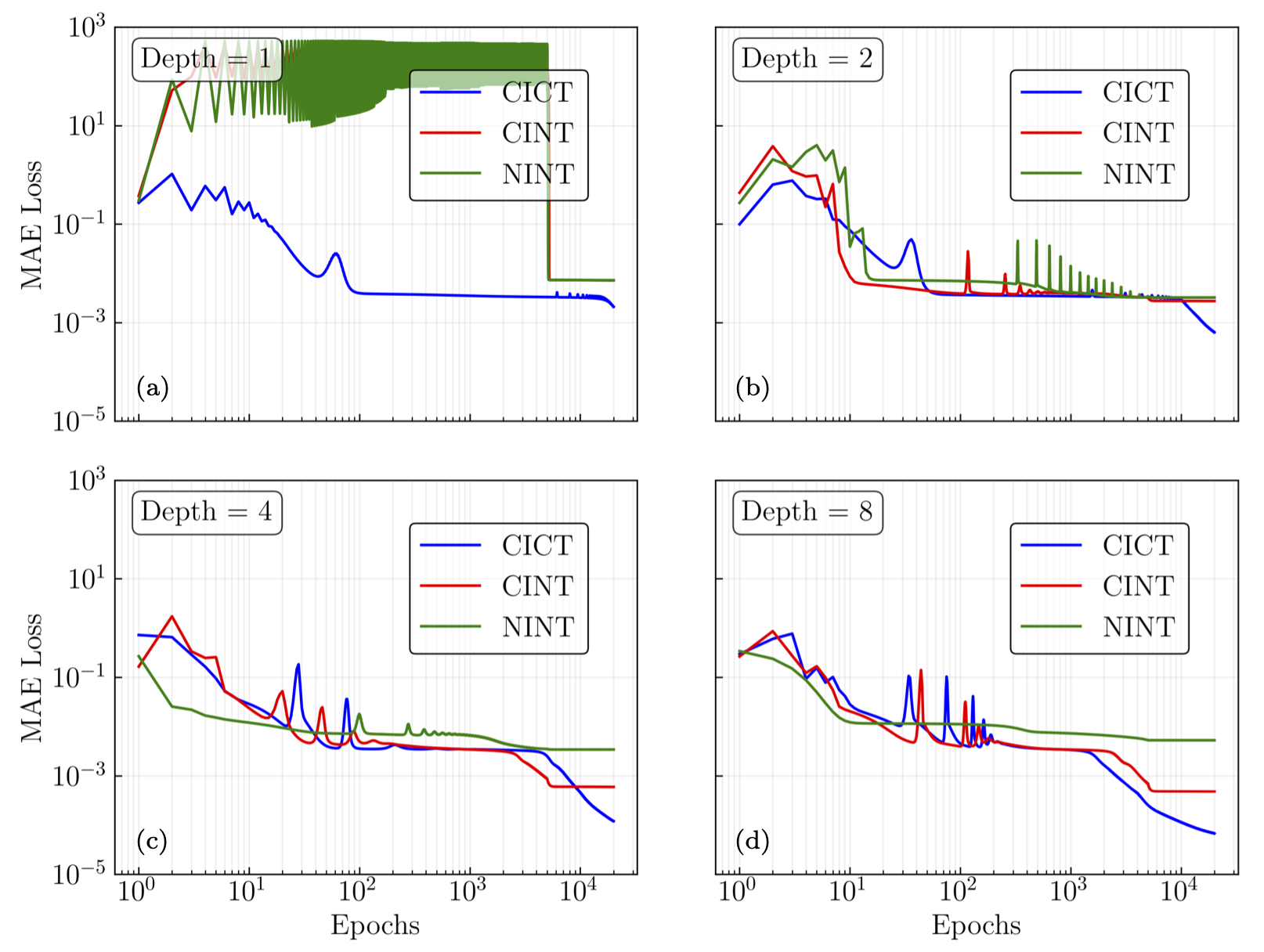
Fig. 32.16 Same as Fig. 32.15 but for Tanh activation functions.#