32.5. Validating ANNFT#
Validating ANNFT training behaviors#
Anatomy of a feed-forward network#
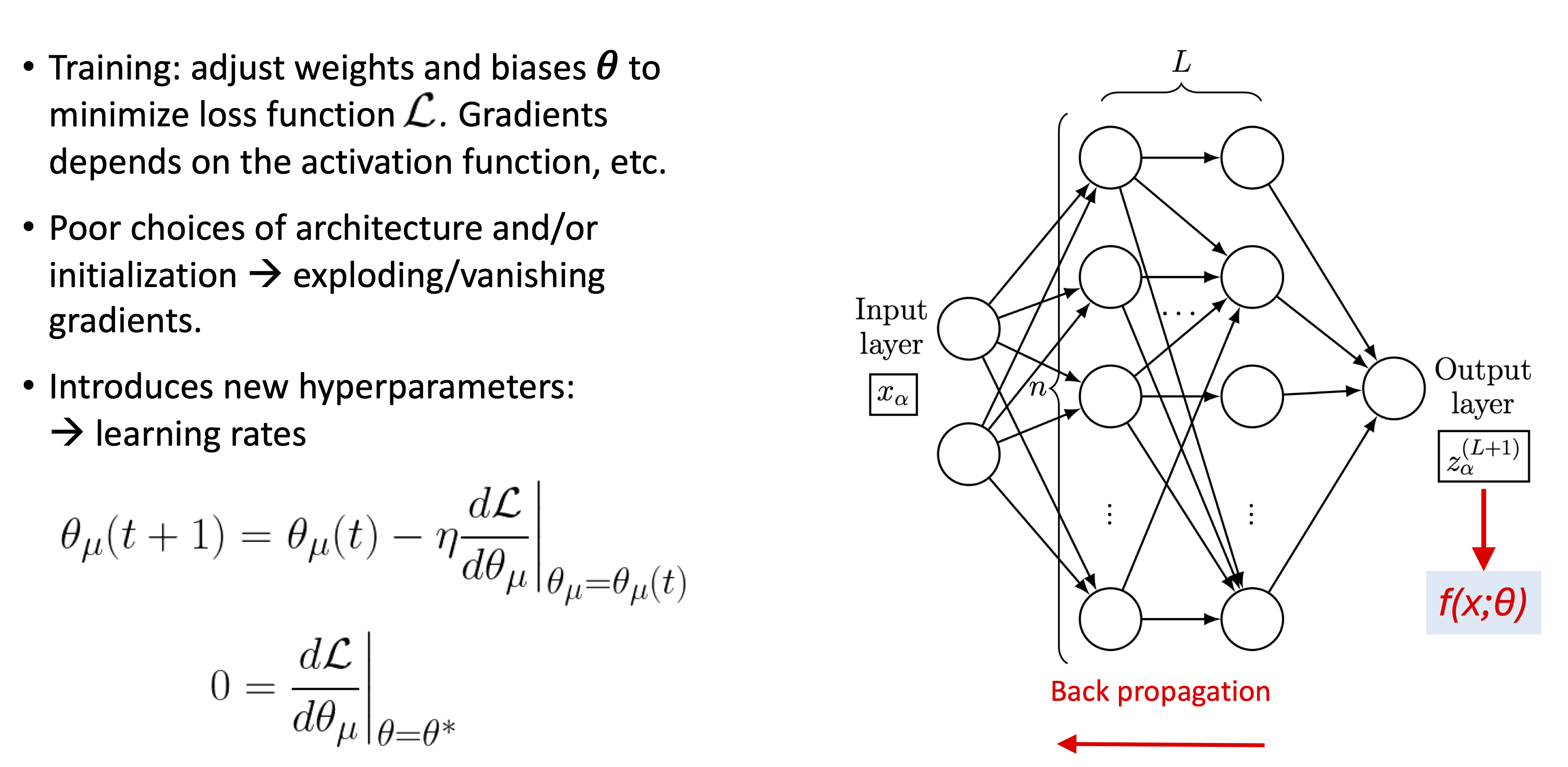
Training and the Theory of Deep Learning#
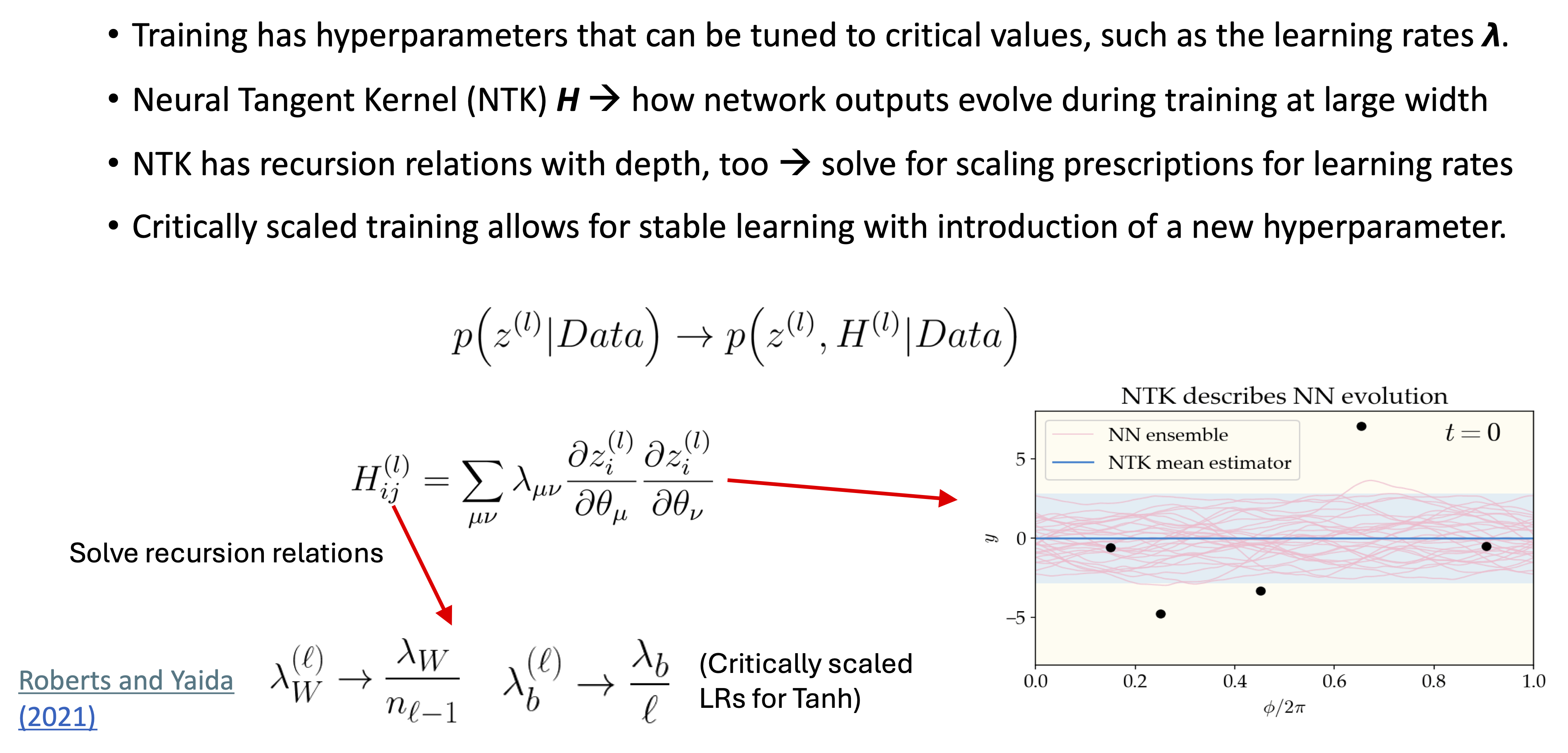
Neural Tangent Kernel Recursion#

Mean RMS deviation between initial and final weights/biases#
ANNFT assumes that the initial network weights and biases are close so that a Taylor series for the trained solution is valid.
The average Frobenius norm of weights and biases was used to judge this.
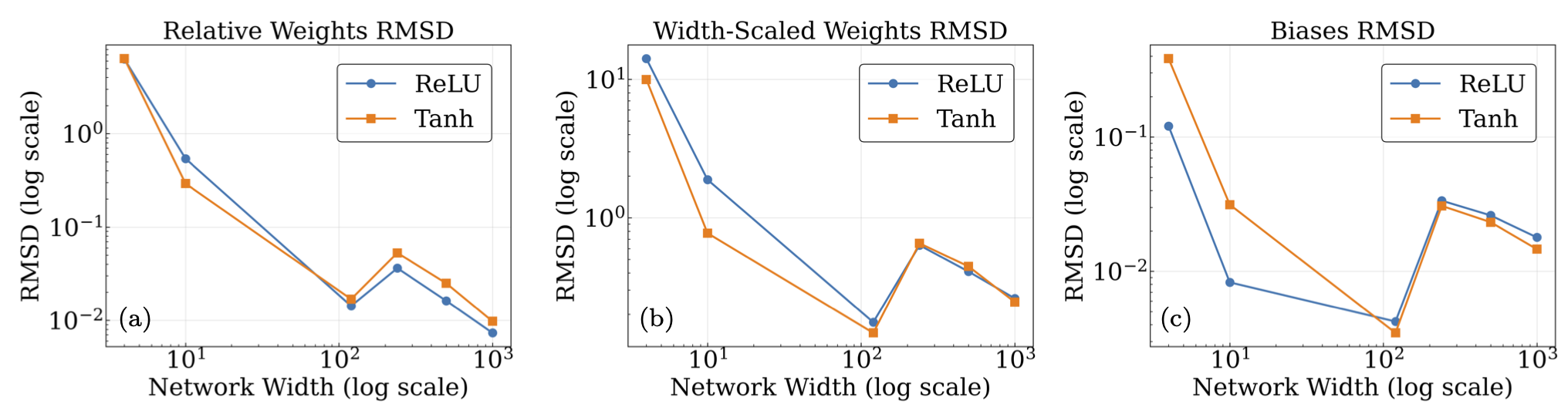
Fig. 32.10 Plots of the mean RMSD between final and initial parameters for the average network hidden layer plotted versus multiple widths (4, 10, 120, 240, 500, 1000). (a) depicts the relative RMSD for the weights (compared to the initial weights), while (b) depicts the absolute RMSD with the weight matrices rescaled by a factor of \(n\) to remove width dependence, and © has the unscaled RMSD for the biases (which are initially zero). Within the regimes useful for training, it can be seen that the changes in parameters are small, a condition required for Taylor expanding around a solution.#
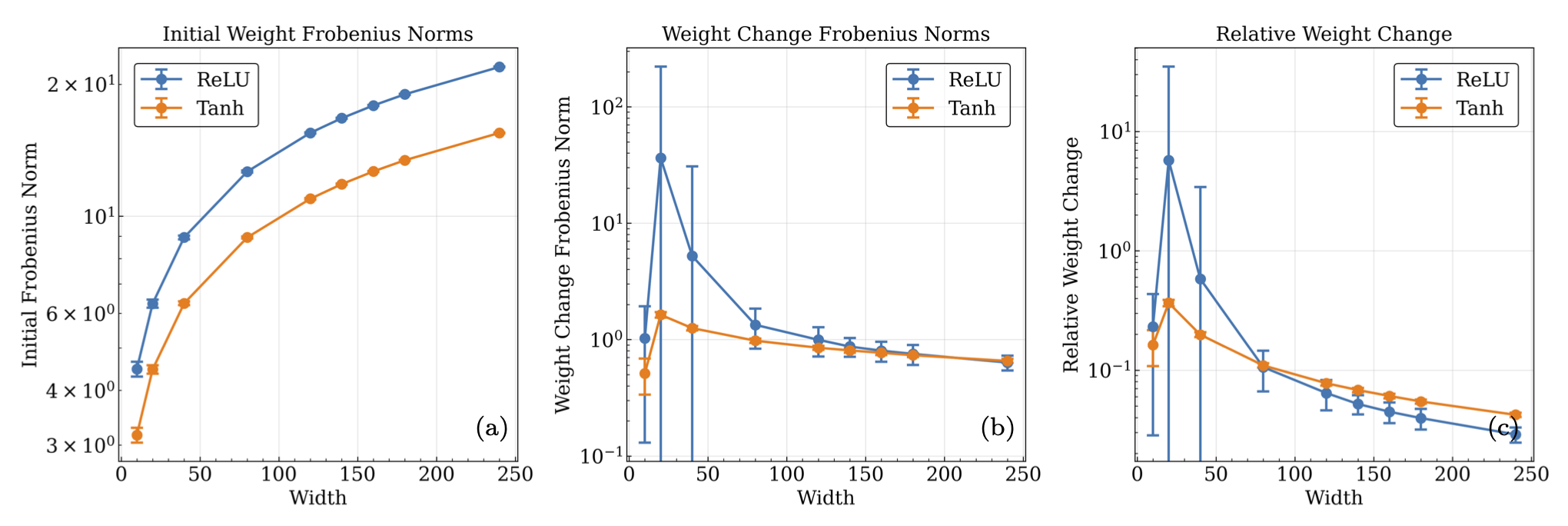
Fig. 32.11 (a) The mean hidden layer Frobenius norms of the pre-training weight matrices, (b) the difference between pre and post training matrices, and (c) the relative difference matrices versus the width of the network containing the matrices. Each norm per width is computed by averaging the mean norm for 100 network trainings of 20000 epochs, with outliers outside of the interquartile range of the distribution of each norm being excluded. The depth of each network configuration was held fixed at 4 layers (\(L=3\),\(\ell_{out}=4\)). The norms give an estimate of the size of the initial parameters, and their absolute and relative difference after training, and their dependence on the width of the network.#
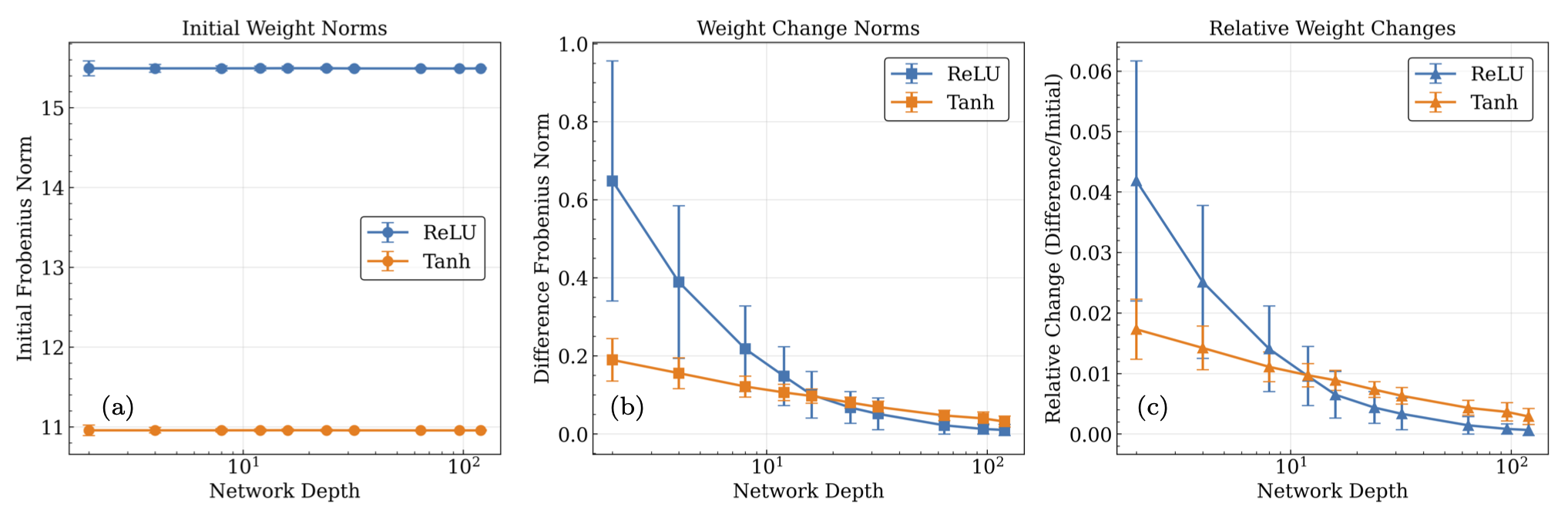
Fig. 32.12 Same as Fig. 32.11 but now with fixed width instead of depth. (a) The mean hidden layer Frobenius norms of the pre-training weight matrices, (b) the difference between pre and post training matrices, and (c) the relative difference matrices versus the depth of the network containing the matrices. Each norm per depth is computed by averaging the mean norm for 100 network trainings of 20000 epochs, with outliers outside of the interquartile range of the distribution of each norm being excluded. The width was held fixed at 120 neurons per hidden layer. The norms give an estimate of the size of the initial parameters, and their absolute and relative difference after training, and their dependence on the depth of the network.#