12.2. Assigning probabilities (II): The principle of maximum entropy#
Having dealt with ignorance, let us move on to more enlightened situations.
Consider a die with the usual six faces that was rolled a very large number of times. Suppose that we were only told that the average number of dots was 2.5. What (discrete) pdf would we assign? I.e. what are the probabilities \(\{ p_i \}\) that the face on top had \(i\) dots after a single throw?
The available information can be summarized as follows
This is obviously not a normal die, with uniform probability \(p_i=1/6\), since the average result would then be 3.5. But there are many candidate pdfs that would reproduce the given information. Which one should we prefer?
It turns out that there are several different arguments that all point in a direction that is very familiar to people with a physics background. Namely that we should prefer the probability distribution that maximizes an entropy measure, while fulfilling the given constraints.
It will be shown below that the preferred pdf \(\{ p_i \}\) is the one that maximizes
where the constraints are included via the method of Lagrange multipliers.
The monkey argument#
The monkey argument is a model for assigning probabilities to \(M\) different (discrete) alternatives that satisfy some constraints described by \(I\). The argument goes as follows:
Imagine a very large number of monkeys throwing \(N\) balls into \(M\) equally sized boxes. The final number of balls in box \(i\) is \(n_i\).
The normalization condition is satisfied via \(N = \sum_{i=1}^M n_i\).
The fraction of balls in each box gives a possible assignment for the corresponding probability \(p_i = n_i / N\).
The distribution of balls \(\{ n_i \}\) divided by \(N\) is therefore a candidate pdf \(\{ p_i \}\).
After one round the monkeys have distributed their (huge number of) balls over the \(M\) boxes.
The resulting pdf might not be consistent with the constraints in \(I\), however, in which case it must be rejected as a possible candidate.
The candidate pdf is recorded by an independent observer in the scenario that the constraints are in fact fulfilled.
After many such rounds, some distributions will be found to come up more often than others.
The one that appears most frequently (and satisfies \(I\)) would be a sensible choice for \(p(\{p_i\}|I)\).
Since our ideal monkeys have no agenda of their own to influence the distribution, this most favoured distribution can be regarded as the one that best represents our given state of knowledge.
No bananas are allowed!
Now, let us see how this preferred solution corresponds to the pdf with the largest entropy. Remember in the following that \(N\) (and \(n_i\)) are considered to be very large numbers (\(N/M \gg 1\))
There are \(M^N\) different ways to distribute the balls.
The micro-states corresponding to a particular distribution \(\{ n_i\}\) are all connected to the same pdf \(\{ p_i \}\). Therefore, the frequency of a given pdf is given by
The number of micro-states, \(W(\{n_i\}))\), in the nominator is equal to \(N! / \prod_{i=1}^M n_i!\).
We express the logarithm of this number using the Stirling approximation for factorials of large numbers, \(\log(n!) \approx n\log(n) - n\), and finding a cancellation of \(N-\sum_i n_i\).
Therefore, the logarithm of the frequency of a given pdf is
Substituting \(p_i = n_i/N\), and using the normalization condition finally gives
Recall that the preferred pdf is the one that appears most frequently, i.e., that maximizes the above expression. We further note that \(N\) and \(M\) are constants such that the preferred pdf is given by the \(\{ p_i \}\) that maximizes
You might recognise this quantity as the entropy measure from statistical mechanics. The interpretation of entropy in statistical mechanics is the measure of uncertainty that remains about a system after its observable macroscopic properties, such as temperature, pressure and volume, have been properly taken into account. For a given set of macroscopic variables, the entropy measures the degree to which the probability of the system is spread out over different possible microstates. Specifically, entropy is a logarithmic measure of the number of micro-states with significant probability of being occupied \(S = -k_B \sum_i p_i \log(p_i)\), where \(k_B\) is the Boltzmann constant.
Why maximize the entropy?#
There are a few different arguments for why the entropy should be maximized when assigning probability distributions given some limited information:
Information theory: maximum entropy=minimum information (Shannon, 1948).
Logical consistency (Shore & Johnson, 1960).
Uncorrelated assignments related monotonically to \(S\) (Skilling, 1988).
Consider the third argument. Let us check it empirically in the context of the problem of hair colour and handedness of Scandinavians. We are interested in determining \(p_1 \equiv p(L,B|I) \equiv x\), the probability that a Scandinavian is both left-handed and blonde. However, in this simple example we can immediately realize that the assignment \(p_1=0.07\) is the only one that implies no correlation between left-handedness and hair color. Any joint probability smaller than 0.07 implies that left-handed people are less likely to be blonde, and any larger vale indicates that left-handed people are more likely to be blonde.
As argued, any assignment \(p_1 \neq 0.07\) corresponds to the existence of a correlation that was not explicitly specified in the provided information.
Question
Can you show why \(p_1 < 0.07\) and \(p_1 > 0.07\) corresponds to left-handedness and blondeness being dependent variables?
Let us now empirically consider a few variational functions of \(\{ p_i \}\) and see if any of them gives a maximum that corresponds to the uncorrelated assignment \(x=0.07\). Note that \(x=0.07\) implies \(p_1 = 0.07, \, p_2 = 0.63, \, p_3 = 0.03, \, p_4 = 0.27\). A few variational functions and their prediction for \(x\) are shown in the following table.
Variational function |
argmax \(x\) |
Implied correlation |
|---|---|---|
\(-\sum_i p_i \log(p_i)\) |
0.070 |
None |
\(\sum_i \log(p_i)\) |
0.053 |
Negative |
\(-\sum_i p_i^2 \log(p_i)\) |
0.100 |
Positive |
\(-\sum_i \sqrt{p_i(1-p_i)}\) |
0.066 |
Negative |
The assignment based on the entropy measure is the only one that respects this lack of correlations.
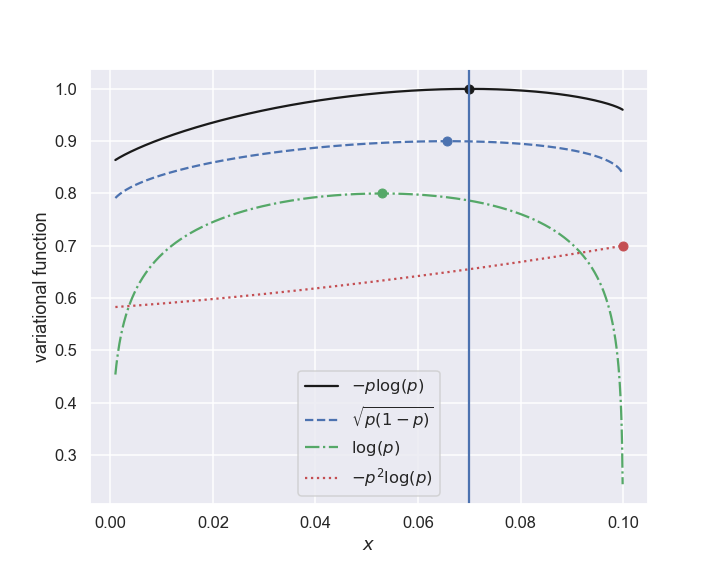
Fig. 12.2 Four different variational functions \(f\left( \{ p_i \} \right)\). The optimal \(x\) for each one is shown by a circle. The uncorrelated assignment \(x=0.07\) is shown by a vertical line.#
Continuous case#
Let us return to the monkeys, but now with different probabilities for each bin. Then
which is often known as the Shannon-Jaynes entropy, or the Kullback number, or the cross entropy (with opposite sign).
Jaynes (1963) has pointed out that this generalization of the entropy, including a Lebesgue measure \(m_i\), is necessary when we consider the limit of continuous parameters.
In particular, \(m(x)\) ensures that the entropy expression is invariant under a change of variables \(x \to y=f(x)\).
Typically, the transformation-group (invariance) arguments are appropriate for assigning \(m(x) = \mathrm{constant}\).
However, there are situations where other assignments for \(m\) represent the most ignorance. For example, in counting experiments one might assign \(m(N) = M^N / N!\) for the number of observed events \(N\) and a very large number of intervals \(M\).
Derivation of common pdfs using MaxEnt#
The principle of maximum entropy (MaxEnt) allows incorporation of further information, e.g. constraints on the mean, variance, etc, into the assignment of probability distributions.
In summary, the MaxEnt approach aims to maximize the Shannon-Jaynes entropy and generates smooth functions.
Mean and the Exponential pdf#
Suppose that we have a pdf \(p(x|I)\) that is normalized over some interval \([ x_\mathrm{min}, x_\mathrm{max}]\). Assume that we have information about its mean value, i.e.,
Based only on this information, what functional form should we assign for the pdf that we will now denote \(p(x|\mu)\)?
Let us use the principle of MaxEnt and maximize the entropy under the normalization and mean constraints. We will use Lagrange multipliers, and we will perform the optimization as a limiting case of a discrete problem; explicitly, we will maximize
Setting \(\partial Q / \partial p_j = 0\) we obtain
With a uniform measure \(m_j = \mathrm{constant}\) we find (in the continuous limit) that
The normalization constant (related to \(\lambda_0\)) and the remaining Lagrange multiplier, \(\lambda_1\), can easily determined by fulfilling the two constraints.
Assuming, e.g., that the normalization interval is \(x \in [0, \infty[\) we obtain
The constraint for the mean then gives
So that the properly normalized pdf from MaxEnt principles becomes the exponential distribution
Variance and the Gaussian pdf#
Suppose that we have information not only on the mean \(\mu\) but also on the variance
The principle of MaxEnt will then result in the continuum assignment
Assuming that the limits of integration are \(\pm \infty\) we can determine both the normalization coefficient and the Lagrange multiplier. After some integration this results in the standard Gaussian pdf
The normal distribution
This indicates that the normal distribution is the most honest representation of our state of knowledge when we only have information about the mean and the variance.
Notice. These arguments extend easily to the case of several parameters. For example, considering \(\{x_k\}\) as the data \(\{ D_k\}\) with error bars \(\{\sigma_k\}\) and \(\{\mu_k\}\) as the model predictions, this allows us to identify the least-squares likelihood as the pdf which best represents our state of knowledge given only the value of the expected squared-deviation between our predictions and the data
If we had convincing information about the covariance \(\left\langle \left( x_i - \mu_i \right) \left( x_j - \mu_j \right) \right\rangle\), where \(i \neq j\), then MaxEnt would assign a correlated, multivariate Gaussian pdf for \(p\left( \{ x_k \} | I \right)\).
Poisson distribution#
The constraints are normalization and a known mean:
\(\Lra\) maximize
with uniform \(m(x)\). The maximization is again straightforward:
Finally, we determine \(\lambda_0\) and \(\lambda_1\) from the constraints:
Substituting we get the Poisson distribution:
Log normal distribution#
Suppose the constraint is on the variance of \(\ln x\), i.e.,
Change variables to \(y=\log(x/x_0)\). What is the constraint in terms of \(y\)?
Now maximize the entropy, subject to this constraint, and, of course, the normalization constraint.
You should obtain the log-normal distribution:
When do you think it would make sense to say that we know the variance of \(\log(x)\), rather than the variance of \(x\) itself?
l1-norm#
Finally, we take the constraint on the mean absolute value of \(x-\mu\): \(\langle |x-\mu| \rangle=\epsilon\).
This constraint is written as:
Use the uniform measure, and go through the steps once again, to show that:
Try other examples!